Vào cuối năm 2015, JR Oakes và đồng nghiệp của mình đã tiến hành một thử nghiệm để thử dự đoán về xếp hạng Google cho một trang web sử dụng máy-học. Dưới đây là những phát hiện của họ, là thứ mà họ muốn chia sẻ với cộng đồng SEO.
Máy-học đang nhanh chóng trở thành một công cụ không thể thiếu với nhiều công ty lớn. Mọi người chắc đều đã nghe về việc thuật toán trí thông minh nhân tạo của Google đánh bại nhà vô địch cờ vây thế giới, cũng như các kỹ thuật như RankBrain, tuy nhiên máy-học không phải một chủ đề thần bí của riêng các nhà nghiên cứu toán học. Có rất nhiều thư viện dễ tiếp cận và các công nghệ hứa hẹn rất hữu dụng cho bất cứ nghành nào có dữ liệu để xử lý.
Máy-học cũng có khả năng thay đổi hoàn toàn việc marketing truyền thống qua web và SEO. Cuối năm ngoái tôi cùng đồng nghiệp bắt đầu một thử nghiệm trong đó chúng tôi đưa vài thuật toán máy-học thông dụng vào công việc dự đoán xếp hạng trong Google. Cuối cùng chúng tôi có một tập hợp đạt được 41 phần trăm đúng dương tính và 41 phần trăm đúng âm tính với bộ dữ liệu của mình.
Ở phần tiếp theo, tôi sẽ nói với các về thử nghiệm của chúng tôi, và tôi sẽ bàn luận về một số thư viện quan trọng và các công nghệ quan trọng với giới SEO ở bước đầu tìm hiểu.
Thử nghiệm của chúng tôi
Đến cuối năm 2015, chúng tôi bắt đầu nghe nhiều hơn về máy-học và hứa hẹn của nó về việc sử dụng một lượng lớn dữ liệu. Càng tìm hiểu thêm, nó lại càng mang nặng tính kỹ thuật hơn, và chúng tôi nhanh chóng hiểu là sẽ hữu ích nếu có ai đó chỉ dẫn cho mình trong lĩnh vực này.
Vào lúc đó, chúng tôi có gặp một nhà khoa học dữ liệu từ Brazil có tên Alejandro Simkievich. Điều thú vị với chúng tôi về Simkievich đó là ông ấy làm việc trong lĩnh vực tìm kiếm liên quan và tối ưu hóa tỷ lệ chuyển đổi và tổ chức rất tốt các cuộc thi đấu Kaggle quan trọng. (Với những ai chưa biết thì Kaggle là một trang web tổ chức các cuộc thi đấu máy-học cho các nhóm các nhà khoa học dữ liệu và những người đam mê máy-học).
Simkievich là chủ của Statec, một công ty tư vấn khoa học dữ liệu/máy-học, với khách hàng là người tiêu dùng trong lĩnh vực hàng hóa, xe cộ, marketing và internet. Rất nhiều công việc do Statec tiến hành tập trng vào việc đánh giá sự phù hợp của các công cụ tìm kiếm thương mại điện tử. Làm việc với họ dường như là rất phù hợp bởi chúng tôi theo đuổi việc sử dụng dữ liệu để giúp cho việc ra quyết định của SEO.
Chúng tôi muốn đặt ra các mục tiêu lớn vì thế chúng tôi quyết định sẽ xem xem liệu chúng tôi có thể sử dụng các dữ liệu có được từ các trình thu thập, các công cụ theo dấu thứ hạng, các công cụ về liên kết và một số công cụ khác, xem liệu chúng tôi có thể tạo ra các tính năng cho phép mình dự đoán thứ hạng của một trang web không. Trong khi chúng tôi biết rằng khả năng thành công theo hướng đó là rất thấp, chúng tôi vẫn tiến hành vì cơ hội thành công nào đó cũng như cơ hội để học hỏi những kỹ thuật thực sự thú vị.
Dữ liệu
Về cơ bản, máy-học sử dụng các chương trình máy tính để lấy dữ liệu và chuyển hóa chúng theo một cách đem lại những thứ có giá trị. “Chuyển hóa” là một từ không hẳn chuẩn xác, vì nó không nói hết được những gì liên quan, nhưng nó được lựa chọn vì dễ hiểu. Vấn đề ở đây là mọi máy-học đều bắt đầu với vài kiểu dữ liệu đầu vào.
(Ghi chú: Có rất nhiều hướng dẫn và các khóa học miễn phí rất tốt trong việc nói về các vấn đề cơ bản của máy-học, vì thế chúng tôi sẽ không làm việc này ở đây. Nếu bạn thích tìm hiểu thêm, Andrew Ng có một lớp học miễn phí tuyệt vời trên Coursera ở đây: https://www.coursera.org/learn/machine-learning/).
Tóm lại là chúng ta phải tìm dữ liệu mà chúng ta có thể sử dụng để huấn luyện một mô hình máy-học. Lúc này chúng tôi không biết chính xác thứ gì sẽ hữu ích, vì vậy chúng tôi sử dụng hướng tiếp cận tổng hợp và thu nhặt nhiều tính năng nhất mà chúng tôi có thể nghĩ đến. GetStat và Majestic rất hữu ích trong việc cung cấp nhiều dữ liệu cơ bản, và chúng tôi xây dựng một trình thu thập dữ liệu để thu thập mọi thứ khác.
Mục tiêu của chúng tôi là kết thúc với đủ dữ liệu để huấn luyện thành công một mô hình (sẽ nói thêm về điều này về sau), và điều đó có nghĩa là rất nhiều dữ liệu. Với mô hình đầu tiên, chúng ta có khoảng 200.000 quan sát (hàng) và 54 thuộc tính (cột).
Một chút kiến thức cơ bản
Như đã nói từ trước, tôi sẽ không nói chi tiết nhiều về máy-học, nhưng quan trọng là nắm được vài điểm để hiểu được phần tiếp theo. Về tổng thể, phần lớn công việc của máy-học hiện nay là các thuật toán về hồi quy, phân cấp và phân nhóm. Tôi sẽ định nghĩa hai việc đầu tiên, vì chúng liên quan đến dự án của chúng tôi.
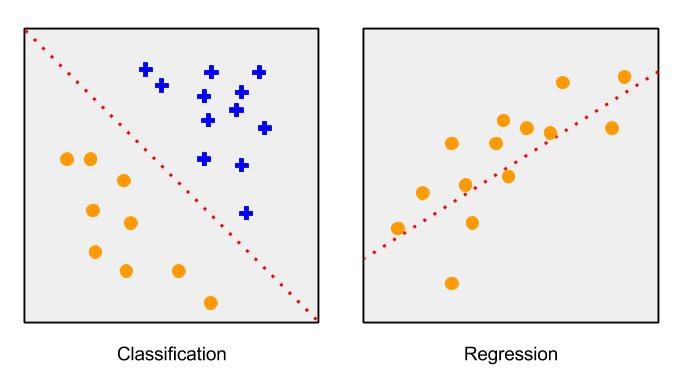
• Các thuật toán hồi quy thường hữu ích trong việc dự đoán một con số đơn lẻ. Nếu bạn muốn tọa ra một thuật toán dự đoán giá cổ phiếu dựa trên các tính năng của cổ phiếu, bạn sẽ lựa chọn kiểu mô hình này. Chúng được gọi là các biến liên tục.
• Các thuật toán phân cấp được sử dụng để dự đoán về một thành phần của một tập hợp các câu trả lời. Nó có thể là sự phân loại đơn giản “có hoặc không”, hoặc “đỏ, xanh lá, xanh biển”. Nếu bạn muốn dự đoán về việc một người không rõ danh tính là nam hay nữ từ các tính năng, bạn sẽ chọn kiểu mô hình này. Chúng được gọi là các biến rời rạc.
Máy-học hiện thời là một vấn đề thiên về kỹ thuật, và nhiều công việc tiên tiến đòi hỏi sự hiểu biết về đại số tuyến tính, giải tích, các ký hiệu toán học và các ngôn ngữ lập trình như Python. Một trong những mục giúp tôi hiểu được tổng thể ở một mức độ dễ tiếp cận, là việc nghĩ các mô hình máy-học như việc thêm đối trọng vào các tính năng trong dữ liệu mà bạn đưa cho nó. Tính năng càng quan trọng thì đối trọng càng lớn.
Khi bạn đọc về “các mô hình huấn luyện”, hãy tưởng tượng một sợi dây kết nối với mô hình đó với mỗi đối trọng, và khi mô hình đó tiến hành một dự đoán, một hàm định giá được sử dụng để nói cho bạn biết dự đoán đó sai đến đâu và để nhẹ nhàng hoặc nghiêm khắc kéo sợi dây về hướng câu trả lời đúng, điều chỉnh đúng lại tất cả các đối trọng.
Phần tiếp theo sẽ có các thuật ngữ mang tính kỹ thuật, vì thế nếu nó quá khó hiểu với bạn, hãy bỏ qua để đến với phần kết quả và kết luận ở cuối.
Đương đầu với xếp hạng của Google
Giờ chúng tôi đã có các dữ liệu, chúng tôi đã thử vài cách tiếp cận với việc dự đoán thứ hạng của Google với mỗi trang web.
Đầu tiên chúng tôi sử dụng thuật toán hồi quy. Đó là chúng tôi tìm cách để dự đoán thứ hạng chính xác của một trang web với một cụm tìm kiếm cho trước (ví dụ: một trang được xếp hạng X với cụm tìm kiếm Y), nhưng sau vài tuần chúng tôi nhận ra việc này quá khó khăn. Đầu tiên, thứ hạng là việc định nghĩa một đặc tính của một trang liên quan tới các trang khác, không phải đặc tính nội tại của trang đó (ví dụ như là số lượng từ). Vì việc chạy thuật toán của chúng tôi với tất cả các trang được xếp hạng với một cụm tìm kiếm cho trước là không thể, chúng tôi đã xây dựng lại vấn đề.
Chúng tôi nhận ra rằng, với việc xếp hạng của Google, điều quan trọng nhất là trang web có tồn tại ở trang đầu với một cụm tìm kiếm cho trước hay không. Vì thế chúng tôi xây dựng lại vấn đề: Nếu như chúng tôi cố dự đoán xem một trang web sẽ tồn tại ở trong top 10 trang xếp hạng bởi Google cho một cụm tìm kiếm cụ thể thì sao? Chúng tôi chọn top 10 vì như mọi người nói, bạn có thể giấu cả một xác chết ở trang hai!
Với quan điểm đó, vấn đề trở thành một vấn đề phân loại nhị phân (có hoặc không), khi chúng tôi có hai nhóm: a) trang web ở trong top 10 và b) trang web không ở top 10. Thêm nữa, thay vì việc dự đoán nhị phân, chúng tôi quyết định dự đoán về khả năng mà một trang web cho trước thuộc vào mỗi nhóm.
Sau đó, để buộc bản thân ra các quyết định rõ ràng, chúng tôi quyết định một mức mà nếu trên đó chúng tôi dự đoán trang web sẽ ở top 10. Ví dụ như chúng tôi quyết định mức đó là 0.85 thì nếu chúng tôi dự đoán khả năng một trang web ở top 10 cao hơn 0.85, chúng tôi sẽ dự đoán là trang web đó ở trong top 10.
Để đo lường hiệu năng của thuật toán, chúng tôi quyết định sử dụng một ma trận nhầm lẫn (confusion matrix).
Đồ thị dưới đây thể hiện tổng quan về toàn bộ quy trình.
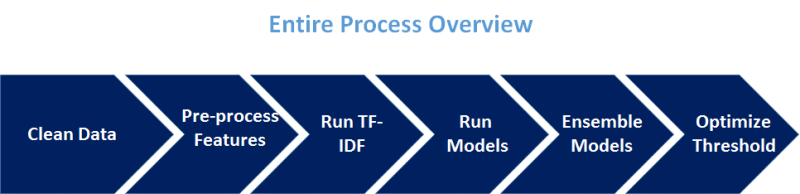
Dọn dẹp dữ liệu
Chúng tôi sử dụng một bộ dữ liệu gồm 200,000 bản ghi, bao gồm khoảng 2,000 từ khóa/cụm tìm kiếm.
Về cơ bản chúng tôi có thể nhóm các thuộc tính mà mình sử dụng thành ba nhóm:
• Các tính năng số học
• Các biến số chủng loại
• Các tính năng văn bản
Các tính năng số học là những thứ có thể làm việc với bất cứ con số nào trong một khoảng thời gian vô hạn hoặc hữu hạn. Vài tính năng số học chúng tôi sử dụng là độ dễ để đọc, mức độ điểm số, độ dài chữ, số chữ trung bình trên một câu, độ dài đường dẫn, thời gian tải trang, số tên miền đề cập đến trang, số tên miền .edu đề cập đến trang, số tên miền .gov đề cập đến trang, Trust Flow (chỉ số đánh giá chất lượng liên kết trỏ về trang web) cho một số lượng chủ đề, Citation Flow (số lượng liên kết trỏ về trang web), các chia sẻ Facebook, các chia sẻ LinkedIn và Google. Chúng tôi áp dụng một vô hướng chuẩn (bộ nhân) vào các tính năng để hướng chúng vào quanh giá trị trung bình, nhưng ngoài ra chúng không đòi hỏi phải xử lý thêm gì.
Một biến số chủng loại là thứ có thể làm việc với một số lượng giới hạn của các giá trị, với mỗi giá trị thể hiện một nhóm hoặc loại khác nhau. Các biến số chủng loại chúng tôi sử dụng bao gồm các từ khóa thường xuyên nhất, cũng như các vị trí và các tổ chức trên khắp các trang web, thêm vào đó là các chủ đề mà với chúng trang web được tin cậy. Việc xử lý trước các tính năng này bao gồm chuyển đổi chúng thành các nhãn số học và sau đó là mã hóa one-hot.
Các tính năng văn bản rõ ràng là bao gồm văn bản chữ. Chúng gồm cụm tìm kiếm, nội dung trang web, tiêu đề, mô tả meta, đoạn văn bản chứa liên kết, các thẻ heading H3, H2, H1 và các tính năng khác.
Điều quan trọng cần nhấn mạnh đó là không có sự khác nhau rõ ràng giữa vài thuộc tính chủng loại (ví dụ như các tổ chức được nói đến trên trang web) và thuộc tính văn bản, và vài thuộc tính có thể chuyển từ một nhóm này sang nhóm khác với các mô hình khác nhau.
Nguồn: http://searchengineland.com/