Nhà báo Patrick Stox tin rằng sửa chữa các chuyển hướng lịch sử thường là một cách dễ dàng để đạt được các thành công nhanh chóng, và bài báo này cho bạn biết làm thế nào để làm điều đó chỉ bằng cách sử dụng API của Wayback Machine CDX Server.

Nếu bạn phải nói với một công ty là chỉ làm một việc để cải thiện SEO của họ, việc đó sẽ là gì? Bạn sẽ nói việc gì với họ, là một việc sẽ có tác động nhiều nhất với khoảng thời gian ít nhất và sẽ thực sự thúc đẩy họ?
Cá nhân tôi sẽ nói với họ sửa chữa các chuyển hướng lịch sử. Qúa trình này bao gồm việc sửa chữa các chuyển hướng chưa bao giờ làm thực hiện (hoặc sụt giảm theo thời gian) từ các trang cũ trên một trang web tích lũy liên kết và không chuyển các tín hiệu một cách đúng đắn tới các trang hiện tại. Bạn sẽ phục hồi lại các giá trị đã thuộc về trang web của bạn nhưng đã bị mất.
Trong thời gian làm SEO của mình, tôi phải nói rằng sửa chữa các chuyển hướng là một trong nhưng chiến lược mạnh mẽ nhất. Không ai thực sự thích làm chuyển hướng, và thường thì chúng bị bỏ qua hoặc quên đi theo thời gian. Thực sự quan trọng để có một quy trình đảm bảo việc chuyển hướng được hoàn thành, chúng được hoành thành đúng và chúng được cập nhật.
Tôi không thể nói với bạn việc giúp mọi người sau một cuộc di chuyển dữ liệu hỏng hoặc một sự thiết kế lại, hoặc có thể cho thấy sự cải thiện lớn ở đầu một chiến dịch với chỉ vài giờ làm việc là tuyệt thế nào. Bắt đầu hoàn hảo với một khách hàng mới thực sự tăng cường mức độ tin tưởng vào công việc của bạn.
Các liên kết bị thất lạc
Bài báo đầu tiên của tôi trên Search Engine Land “Lấy lại các liên kết bị thất lạc của bạn” (http://searchengineland.com/take-back-lost-links-220462) là về chủ đề này. Trong đó tôi cho thấy một công ty thất bại trong việc triển khai việc chuyển hướng khi thiết kế lại trang web đã thấy một lượng sụt giảm đáng kể trong lượng truy cập của họ thế nào.
Sau khi sửa chữa các chuyển hướng này và thu thập một danh sách các trang đã có trước đó trên các phiên bản cũ hơn của trang wbe từ mục Internet Archive của Wayback Machine, tôi đã sử được các chuyển hướng lịch sử mà không được hoàn thành, hoặc đã bị thất lạc trong các cập nhật theo thời gian, và thấy được lượng truy cập tăng gấp đôi từ mức trước đây trong vòng một tháng.

Tôi đã thấy một chiến lược - sửa chữa các chuyển hướng lịch sử - tạo ra sự khác biệt giữa việc chỉ là một đối thủ cạnh tranh nữa với việc là một tay chơi thực sự ở đỉnh của thị trường.
Ảnh chụp màn hình dưới đây cho thấy một ví dụ gần đây từ đầu tháng Năm năm nay. Khoảng 24 tên miền chứa liên kết trỏ về được phục hồi, theo Ahrefs. Bình thường khi tôi thấy các bước nhảy đột ngột như vậy trong Ahrefs, tôi sẽ xem xét về vấn đề phát tán rác, nhưng trong trường hợp này nó chỉ phục hồi các liên kết tới các trang trên các phiên bản trước đây của trang web mà không tồn tại trong một khoảng thời gian.
Mất bao lâu để có được các liên kết đó với một chiến dịch xây dựng liên kết so với thời gian bỏ ra để sửa chữa vài chuyển hướng?
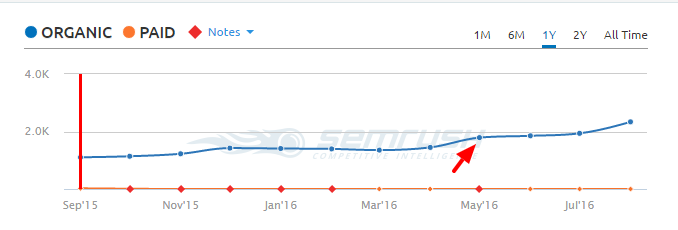
SEMrush cho thấy khoảng 30 phần trăm lượng truy cập bổ sung trong một tháng, tuy nhiên nó thực sự cao hơn một chút, theo dữ liệu Google Analytics.
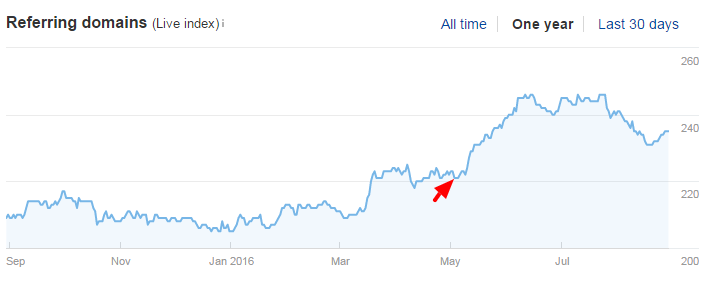
Screaming Frog so với Wayback Machine CDX Server
Trong bài báo trước đây, tôi chọn cách thu thập dữ liệu của Wayback Machine với Screaming Frog. Đây là một cách hoàn chỉnh nhất để thu thập các URI (dùng xác định vị trí một tài nguyên trên mạng), khi mà nó thu thập mọi thứ nó thấy trên mọi trang web đã được lưu trữ, và nó cũng đồng thời cung cấp dữ liệu đầu ra rõ ràng hơn so với việc sử dụng CDX Server (điều mà tôi sẽ nói chi tiết ở phần sau). Nó cung cấp một bức tranh hoàn chỉnh, nhưng phương pháp này thất bại trong việc xử lý các trang web lớn hơn vì các giới hạn bộ nhớ.
Sau khi thuyết trình tại SMX Advanced năm nay, tôi đã có 50 người chú ý và hỏi tôi về một phần cụ thể trong bài thuyết trình của tôi. Điều đáng buồn là điều đó không thực sự ở trong bài thuyết trình của tôi, mà chỉ là một mẹo bổ sung. Thứ thu hút nhiều chú ý đó là gì mà phần còn lại của bài thuyết trình của tôi bị bỏ qua? Đó là thực tế bạn có thể dễ dàng lấy các URI từ Wayback Machine để kiểm tra và sửa chữa các chuyển hướng lịch sử.
Tôi thực sự nói đến việc xuất các URI trong JSON ở bài báo trước như một lựa chọn khác ngoài Screaming Frog, nhưng đây thực sự là phương pháp ưa thích của tôi. Trước khi bạn bỏ chạy vì không muốn làm việc với JSON, bạn nên biết rằng dữ liệu đầu ra của CDX Server mặc định là các ký tự thuần.
Bạn có thể tìm thấy tài liệu đầy đủ cho API của Wayback Machine CDX Server trên GitHub của họ (https://github.com/internetarchive/wayback/tree/master/wayback-cdx-server).
Một truy vấn đơn giản nhất trông giống thế này:
http://web.archive.org/cdx/search/cdx?url=searchengineland.com
http://web.archive.org/cdx/search/cdx?url=searchengineland.com
Nhưng tôi khuyến nghị truy vấn như sau:
https://web.archive.org/cdx/search/cdx?url=searchengineland.com&matchType=domain&fl=original&collapse=urlkey&limit=100000
https://web.archive.org/cdx/search/cdx?url=searchengineland.com&matchType=domain&fl=original&collapse=urlkey&limit=100000
Phân tích truy vấn này:
• &matchType=domain cho tôi tất các kết quả từ tên miền và các tên miền con.
• &fl=original cho thấy tôi chỉ muốn các URI. Đây là thứ làm cho dữ liệu đầu ra thực sự rõ ràng, hơn là việc nhận được tất cả các cột.
• &collapse=urlkey đơn giản loại bỏ tất cả các trùng lặp thấy được trên các phiên bản của URI, đưa cho chúng ta chỉ một danh sách cho mỗi trang.
• &limit=100000 giới hạn các kết quả ở mức 100,000 hàng.
Các điều khác mà tôi thấy rất hữu dụng là Resumption Key, thứ cho phép bạn tiếp tục lại tại chỗ bạn bỏ qua cho các truy vấn thực sự lớn, hoặc sử dụng API Pagination cho các truy vấn lớn này, nó sẽ một lần nữa chia nhỏ dữ liệu thành nhiều phần. Đọc các tài liệu về việc làm thế nào để sử dụng những thứ này khi bạn cần đến chúng.
Một lựa chọn khác tôi thấy bản thân sử dụng thường xuyên đó là bộ lọc Regex. Nó cho phép tôi loại bỏ các tệp khác nhau mà tôi không cần, như là css, jss, ico hoặc trong các trường hợp khác, nếu tôi không muốn các hình ảnh thì tôi lọc ra các tệp jpg, jpeg, gif, png và tương tự như thế.
Làm rõ dữ liệu đầu ra
Chúng ta chưa xong việc ở đây, đáng tiếc là thế. Mặc dù truy vấn bên trên khá là rõ ràng, vẫn có nhiều thứ tôi không muốn thấy trong dữ liệu đầu ra: các hình ảnh, tin tức, robot.txt, các URI kỳ lạ được tạo ra bởi các lý do khác nhau. Tất cả điều này vẫn cần phải được lọc ra. Có lẽ vẫn còn các giao tiếp cần được loại bỏ, các thông số, thẻ chiến dịch cần được loại bỏ, các liên kết lỗi, các ký tự cần được chuyển đổi từ dạng UTF-8 hoặc một số các khả năng khác.
Điều này khác nhau với mỗi trang web, và bạn có thể hoặc sử dụng các bộ lọc CDX Server hoặc đơn giản xóa và thay đổi các dòng hoặc các phần của vãn bản hoặc bảng tính để có được dữ liệu đầu ra mà bạn muốn. Đừng thấy choáng ngợp. Tôi không thể cho bạn thấy mọi khả năng, nhưng với vài kết hợp của các bộ lọc, tìm kiếm và thay thế hoặc làm thủ công, bạn sẽ có một danh sách rõ ràng về các trang web cũ.
Kiểm tra các chuyển hướng
Với một danh sách rõ ràng về các URI, bạn sẽ muốn kiểm tra điều gì xảy ra với các trang web cũ. Tôi vẫn sử dụng Screaming Frog cho việc này, và Dan Sharp đã đang một hướng dẫn cho việc này ở đây (https://www.screamingfrog.co.uk/audit-redirects/). Nếu có lỗi 404, bạn sẽ muốn sửa chúng để phục hồi lại các tín hiệu thất lạc. Với lỗi 302 và 301, tôi vẫn khuyến nghị dọn sạch chúng nhưng các dòng dữ liệu lại mờ nhạt hơn vì lợi ích cho bạn. Vài người trong các bạn có lẽ đã thấy dòng tweet của nhà phân tích xu hướng quản trị web của Google, Gary Illyes:
Lỗi chuyển hướng 30x không làm mất PageRank nữa.
Tôi muốn nói là mỗi lần ai đó từ Google nói các điều như “các lỗi 302 giống như là 301”, tôi đều kiểm ra nó. Tôi thường làm một trong những người phản đối nhiều nhất, vì với kinh nghiệm của tôi, nó không phải thế. Tôi đã chạy vài thử nghiệm từ tháng Mười Hai tới tháng Ba, khi John Mueller từ Google nói rằng lỗi 302 cũng giống như lỗi 301, và tôi vẫn thấy sự sụt giảm khi sử dụng 302.
Tôi bắt đầu lại các thử nghiệm vào ngày hôm sau khi IIlyes đăng dòng tweet trên. Trong khi giờ là quá sớm để đưa ra kết luận (mới chỉ một tháng), và tôi chưa tiến hành phân tích đầy đủ, tôi thực sự bị thuyết phục rằng câu nói trên cuối cùng là đúng với Google (Tôi không thể nói các công cụ tìm kiếm khác có kết quả tương tự). Tôi vẫn khuyến nghị dọn dẹp mạng lưới chuyển hướng và sử dụng 301 là tốt nhất.
Kết luận về các chuyển hướng lịch sử
Có rất nhiều phương pháp để thu thập các trang web lịch sử và sửa các chuyển hướng, nhưng cuối cùng việc quan trọng là bạn sửa chữa chúng. Một lần nữa, đây là một trong những chiến lược tôi thấy nhiều lần là tạo ra các tác động lớn. Hãy nhớ rằng thậm chí sau khi bạn làm việc nay, quan trọng là có các quy tác để thực thi và bảo đảm các chuyển hướng để gìn giữ giá trị của các liên kết có được theo thời gian.
Tôi biết nhiều người sẽ hỏi về những thành quả gì họ có thể kỳ vòng, sự thực là điều đó rất khó để nói. Với một trang web mới, có thể không có thành quả gì; nhưng nếu bạn đã có mặt một thời gian, thay đổi cấu trúc trang web theo thời gian hoặc hợp nhất hoặc di chuyển trang web vào trang chính, thì bạn sẽ có những thành quả đáng kể. Nó phụ thuộc vào việc bao nhiêu dấu hiệu chưa bao giờ vượt qua.
Nếu bạn biết rằng có vài trang web đã từng bị hiện tượng liên kết rác trước đây, thì tôi vẫn khuyến nghị làm việc với các chuyển hướng, nhưng hãy chắc chắn là theo dõi các liên kết đi đến và cập nhật tệp tin khước từ của bạn.
Nguồn: http://searchengineland.com/