Nhà báo JR Oakes chia sẻ nghiên cứu về 500.000 kết quả tìm kiếm cho các truy vấn của ngành dịch vụ giao dịch từ 200 thành phố lớn nhất của Mỹ.
Giới thiệu
Trong vài tháng trước, chúng tôi đã làm việc với một công ty tên Statec (một công ty khoa học dữ liệu tại Brazil) để xây dựng các thuộc tính cho các thuật toán dự đoán. Một trong những cân nhắc đầu tiên khi làm việc với các thuật toán dự đoán đó là chọn lọc các dữ liệu liên quan để huấn luyện chúng.
Chúng tôi khá dè dặt khi tập hợp một danh sách các thuộc tính của trang web mà chúng tôi nghĩ rằng có thể sẽ đem đến giá trị nào đó. Mục tiêu của chúng tôi đơn giản là xem xem với những thuộc tính có sẵn, liệu chúng tôi có dự đoán được thứ hạng của một trang web trên Google không. Chúng tôi đã sớm nhận ra trong quá trình này rằng phải quên đi những dữ liệu không thể tiếp cận và hy vọng điều tốt nhất với những gì chúng tôi có.
Dưới đây là phân tích về những dữ liệu mà chúng tôi thu thập được, làm thế nào chúng tôi thu thập được chúng và những tương quan hữu ích có được từ chúng.
Dữ liệu
Một vấn đề ban đầu đó là chúng tôi cần quyền truy cập vào dữ liệu xếp hạng cho đủ kết quả của trang tìm kiếm để cung cấp đủ dữ liệu huấn luyện. May mắn là GetStat đã khiến điều đó trở nên rất đơn giản. Với GetStat, chúng tôi chỉ đơn giản đưa lên các kết hợp từ khóa trong khắp 25 ngành công nghiệp dịch vụ với vị trí của 200 thành phố hàng đầu ở Mỹ (theo diện tích). Nó đưa đến kết quả là 5.000 cụm tìm kiếm đặc biệt (ví dụ “Charlotte Accountant” lấy từ Charlotte, NC).
Công ty của chúng tôi, Consultwebs, tập trung vào marketing ngành luật, nhưng chúng tôi muốn mô hình của mình được phổ biến hơn. Sau khi tải lên 5.000 cụm tìm kiếm và chờ một ngày, chúng tôi có khoảng 500.000 kết quả tìm kiếm có thể được sử dụng để xây dựng bộ dữ liệu của mình.
Sau khi nhận thấy điều này thật dễ dàng, chúng tôi thu thập các dữ liệu còn lại. Tôi đã xây dựng một số trình thu thập dữ liệu với Node.js, vì thế tôi quyết định sẽ xây dựng một thuộc tính trích xuất trên nền các công việc trước đây. May mắn là Node.js là một hệ sinh thái tuyệt vời cho công việc này. Dưới đây tôi đưa ra một vài thư viện khiến Node trở nên rất tốt trong việc thu thập dữ liệu:
• Aylien TextAPI – Đây là một API của node dành cho các dịch vụ bên thứ ba làm phân tích tâm lý, trích xuất văn bản, tổng hợp, trích xuất khái niệm/từ khóa và nhận dạng tên.
• Natural – Một bộ công cụ xử lý ngôn ngữ tự nhiên rất tuyệt dành cho node. Nó không so sánh được với những gì có trên Python, nhưng khá hữu dụng cho những gì ta cần.
• Text Statistics – Hữu dụng để lấy dữ liệu về độ dài câu, mức độ đọc và những thứ tương tự.
• Majestic – Tôi bắt đầu với việc thu thập dữ liệu của API của họ qua một đoạn lệnh tùy chỉnh, nhưng họ cung cấp dữ liệu rất nhanh, một điều rất tuyệt.
• Cheerio – Một thư viện dễ dùng để phân tích các yếu tố DOM sử dụng đánh dấu kiểu jQuery.
• IPInfo – Không thực sự là một thư viện, nhưng là một API tốt để lấy thông tin máy chủ.
Qúa trình thu thập dữ liệu rất chậm, bởi những giới hạn của các nhà cung cấp API và dịch vụ proxy của chúng tôi. Chúng tôi có lẽ đã tạo ra một cụm máy chủ nhưng kinh phí giới hạn nên chỉ dùng vài API cứ mỗi giây một lần.
Dần dần chúng tôi có được dữ liệu đầy đủ của 500.000 đường dẫn. Dưới đây là vài ghi chú từ kinh nghiệm của tôi với việc thu thập dữ liệu từ các đường dẫn.
• Sử dụng API khi có thể. Aylien rất hữu ích trong những công việc mà thư viện của node không ổn định.
• Tìm một dịch dụ proxy tốt cho phép chuyển đổi giữa các cuộc gọi liên tục.
• Tạo cấu trúc logic cho trang web và các kiểu nội dung có thể gây lỗi. Danh sách Craigslist, PDF hoặc tài liệu Word gây ra các vấn đề trong quá trình thu thập dữ liệu.
• Kiểm tra thường xuyên các dữ liệu thu thập được, đặc biệt trong vài nghìn kết quả đầu tiên, để chắc chắn rằng các lỗi trong quá trình thu thập không gây ra vấn đề gì với cấu trúc của dữ liệu được thu thập.
Kết quả
Chúng tôi đã có báo cáo về kết quả của mình từ việc dự đoán thứ hạng ở một bài viết độc lập, nhưng tôi muốn đánh giá những thông tin thú vị từ dữ liệu mà chúng tôi thu thập được.
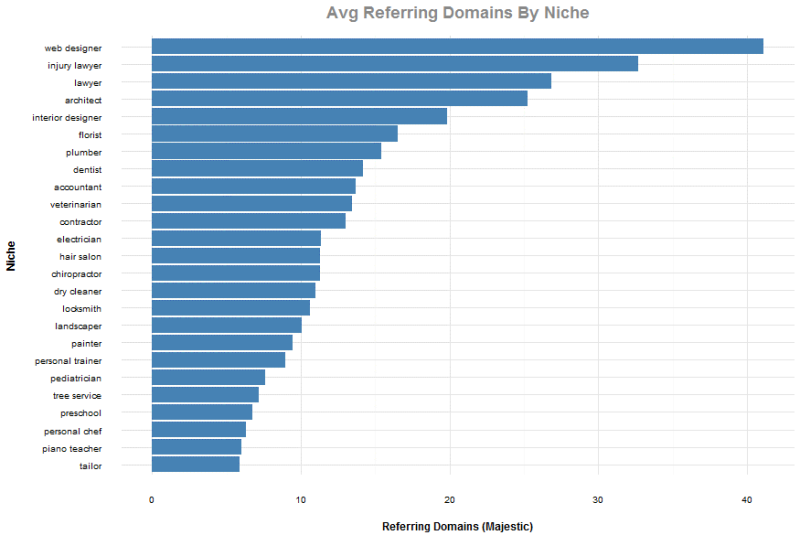
Các thị trường ngách cạnh tranh nhất
Với dữ liệu này, chúng tôi giảm bộ dữ liệu xuống chỉ bảo gồm xếp hạng trong top 20 và đồng thời loại bỏ top bốn phần trăm quan sát dựa trên các tên miền có liên kết trỏ về. Mục đích của việc loại bỏ top bốn phần trăm của các tên miền có liên kết trỏ về là để giữ cho các đường dẫn như Google, Yelp và các trang web lớn khác không có ảnh hưởng đến giá trị trung bình.
Ở biểu đồ dưới đây, chúng tôi cho rằng mục thiết kế web là lớn nhất vì thực tế từ các liên kết từ các trang web hoạt động. Đứng thứ hai không có gì ngạc nhiên với chúng ta, những người làm việc trong lĩnh vực luật pháp.
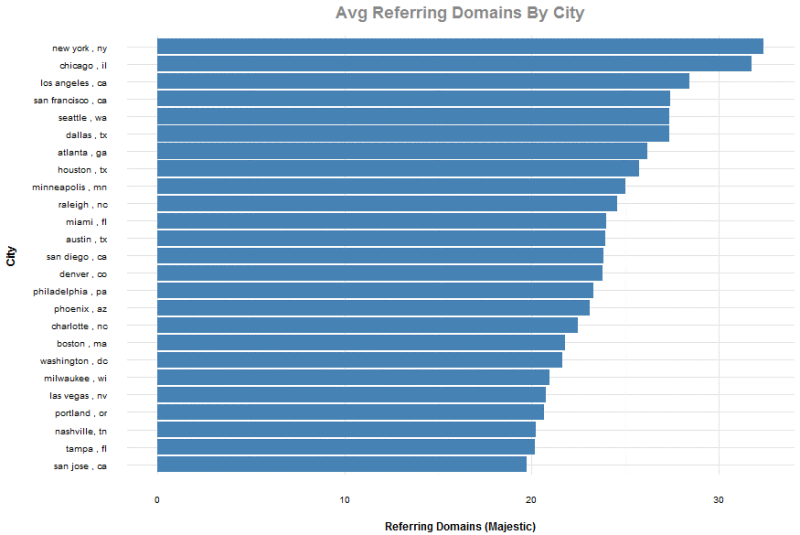
Cạnh tranh liên kết ở top các thành phố
Lại một lần nữa chúng tôi lọc ra kết quả xếp hạng top 20 trong khắp các quan sát và đồng thời loại bỏ top bốn phần trăm quan sát dựa trên các tên miền có liên kết trỏ về để loại bỏ các đường dẫn từ Google, Yelp và các trang web lớn khác. Hãy cứ tự nhiên sử dụng nó trong các báo cáo khi xác định nhu cầu khác hàng ở các thành phố cụ thể.
Các kết quả hàng đầu không có gì ngạc nhiên với chúng ta, những người có khách hàng ở các thành phố này. Cụ thể là New York, là một nhiệm vụ khó khăn với nhiều thị trường ngách.
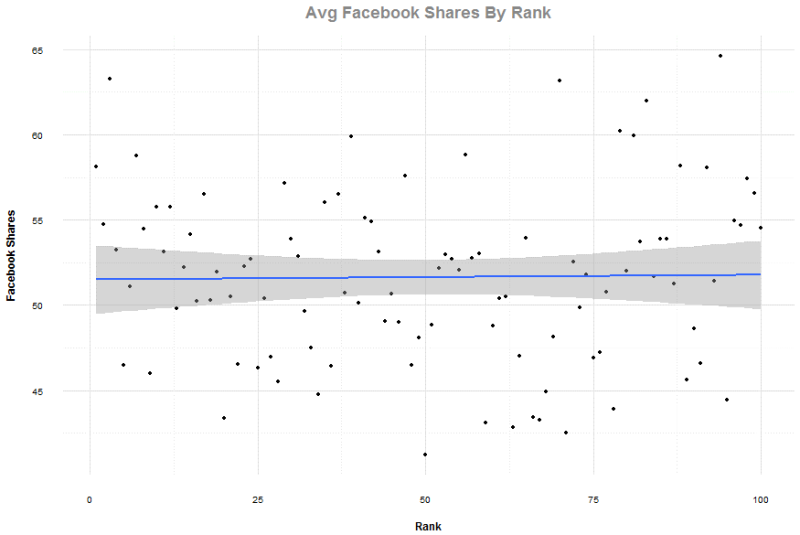
Các chia sẻ Facebook
Với dữ liệu này, chúng tôi giữ xếp hạng đầy đủ của 100 kết quả với mỗi cụm tìm kiếm, nhưng chúng tôi loại bỏ các quan sát với các tên miền chứa liên kết trỏ về ở mức trên top bốn phần trăm và trên 5.000 chia sẻ Facebook. Đây là một sự rút gọn nhỏ so với tổng thể dữ liệu, nhưng khiến cho các điểm dữ liệu gọn gàng hơn.
Đồ thị dưới khiến tôi liên tưởng đến việc ra trường bắn, mà ở đó không có thứ tự nào để bắn. Tương qua Pearson của trung bình chia sẻ để xếp hạng là 0.016 và bạn có thể thấy ở đồ thị đó là rất khó tìm ra liên quan giữa Facebook và bất cứ tác động nào đến xếp hạng với kiểu trang web này.
Citation Flow theo Majestic (CF - số lượng liên kết trỏ về trang web)
Với CF, chúng tôi giữ lại đầy đủ 100 kết quả với từng cụm tìm kiếm, nhưng chúng tôi một lần nữa loại bỏ top bốn phần trăm của các tên miền chứa liên kết trỏ về. Không ngạc nhiên với những ai sử dụng thông số này, có một tương quan lớn -0.872 giữa điểm CF trung bình và vị trí xếp hạng. Đây là quan hệ tỷ lệ nghịch vì thứ hạng sẽ thấp đi khi điểm CF cao hơn. Đây là một lý do tốt để dùng CF.
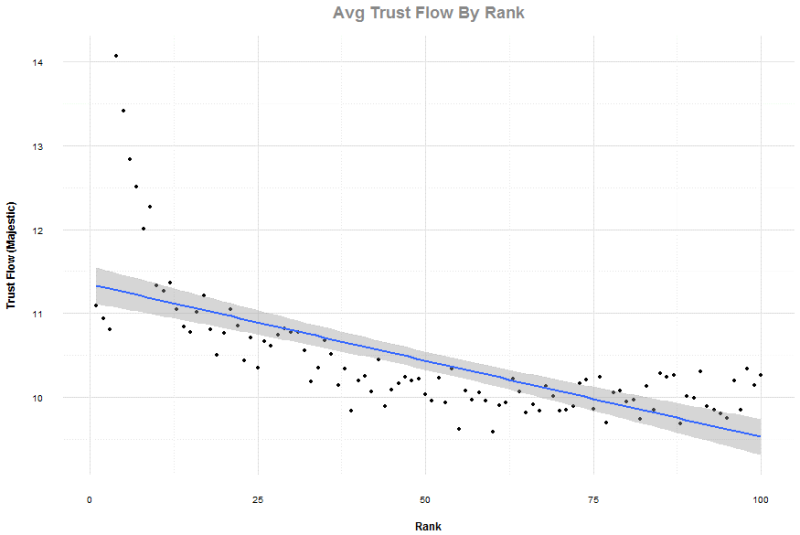
Trust Flow theo Majestic (TF - chỉ số đánh giá chất lượng liên kết trỏ về trang web)
Với TF, chúng tôi giữ đủ 100 kết quả cho mỗi cụm tìm kiếm, nhưng lại lần nữa loại bỏ top bốn phần trăm của các tên miền chứa liên kết trỏ về. Tương quan không mạnh như CF nhưng cũng tương tối mạnh ở mức -0.695. Một lưu ý thú vị ở đồ thị này là quỹ đạo đồ thị đi lên thẳng khi bạn lọt vào top 20 kết quả. Cũng lưu ý rằng vị trí từ 1 đến 3 có thể sai lệch vì tác động của các thông số khác ở kết quả địa phương.
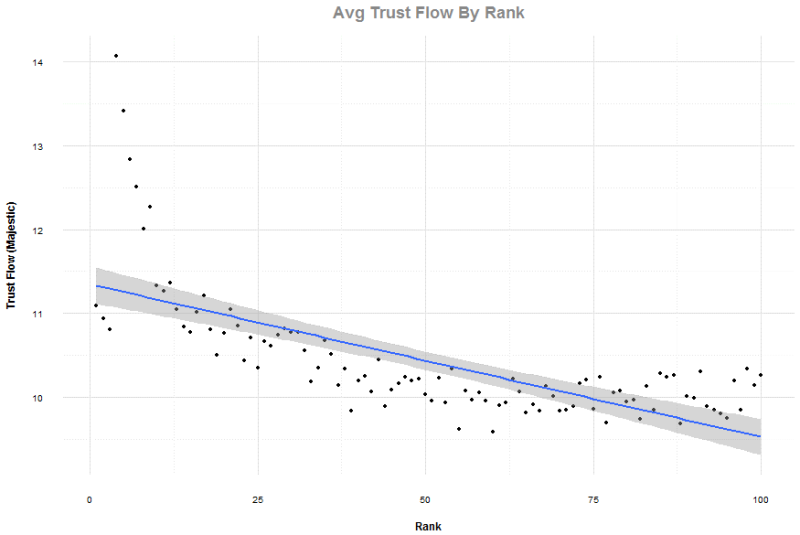
Thời gian phản hồi
Tốc độ đã trở thành tiên quyết với mọi người ngày nay, với việc Google tập trung vào nó và các dự án mới như AMP (https://www.ampproject.org/). Vì những hạn chế trong thu thập dữ liệu, chúng tôi chỉ có thể đo lường thời gian để máy chủ đưa nội dung của trang đến với chúng tôi. Chúng tôi muốn cẩn thận không gọi điều này là thời gian tải trang, như nó thường được xem là thời gian để trình duyệt của bạn tải và tạo trang. Cũng có sự xem xét về độ trễ gặp phải giữa máy chủ của chúng tôi (AWS) với dịch vụ lưu trữ, nhưng chúng tôi nghĩ tổng gộp các sai lệch trong kết quả sẽ là không đáng kể.
Lại một lần nữa, 100 kết quả cho mỗi cụm tìm kiếm, với việc loại bỏ top bốn phần trăm các tên miền chứa liên kết trỏ về. Tương quan Pearson là 0.414, chỉ báo một quan hệ giữa thời gian phản hồi và thứ hạng.
Mặc dù tương tự như tương quan tìm ra bởi Backlinko cho HTTPS, điều này có thể được giải thích rằng các trang web vận hành và được tối ưu tốt hơn có xu hướng đứng đầu. Trong các phát hiện của Backlinko, tôi thắc mắc về việc liệu nó có chính xác khi kết nối HTTPS với ưu tiên xếp hạng của Google hoặc với thực tế rằng trong nhiều ngành dọc, các kết quả top bị chi phối bởi các thương hiệu có xu hướng hướng tới HTTPS.
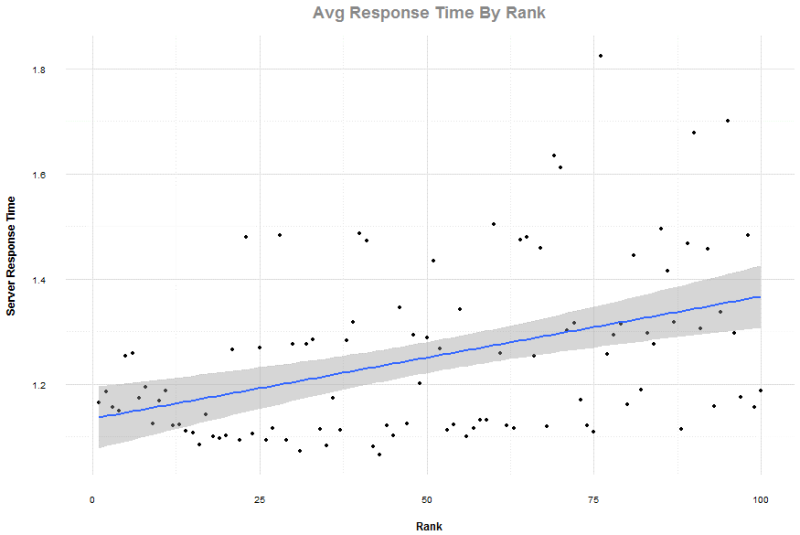
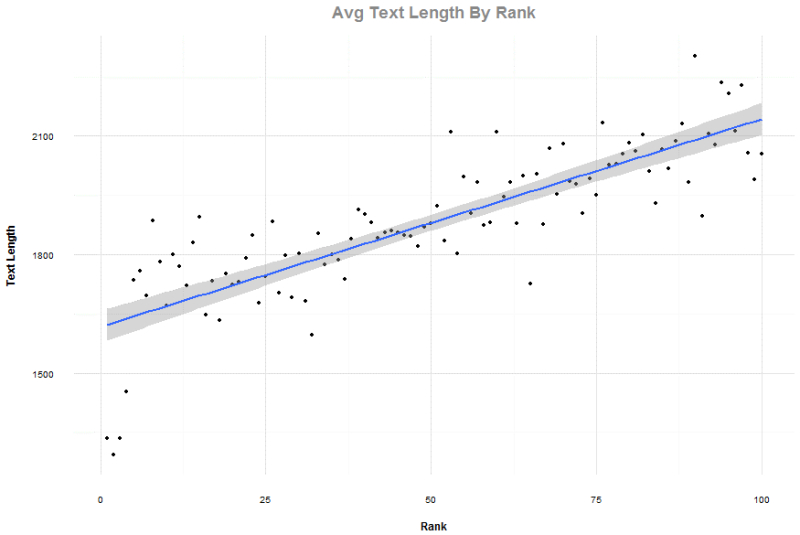
Độ dài văn bản
Điều này với tôi có chút ngạc nhiên, nhưng hãy nhớ rằng các từ khóa trong dữ liệu này có tính giao dịch và không phải là các kết quả gợi ý Wikipedia thông thường. 100 kết quả đầy đủ được sử dụng, cũng như top bốn phần trăm bởi các tên miền chứa liên kết trỏ về bị loại bỏ.
Tương quan Pearson với thứ hạng là 0.829, cho thấy rằng nội dung dài hơn không phải chính yếu. Hãy nhớ rằng các kết quả tìm kiếm địa phương có mặt, và quan trọng hãy nhớ rằng độ dài văn bản được đo lường bằng số ký tự và có thể được chuyển đổi thành từ ngữ một cách trung bình bằng cách chia cho 4.5.
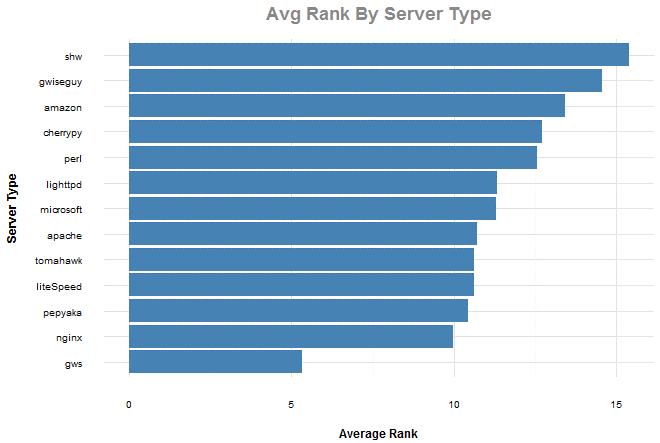
 Kiểu máy chủ
Kiểu máy chủ
Một trong những thuộc tính mà chúng tôi thu thập đó là kiểu máy chủ. Dữ liệu này được lấy từ máy chủ phản hồi với header “server” và được chia thành từ 1 đến 13 chủng loại. Chúng tôi giới hạn kết quả ở top 20 với mỗi cụm tìm kiếm, và không đặt bộ lọc nào với tên miền chứa liên kết trỏ về.
Thêm nữa, chúng tôi bỏ qua những loại không được xác định hoặc không có mặt thường xuyền trong bộ dữ liệu. Kiểu “GWS” là Google Web Services. Thứ hạng trung bình thấp hơn có thể được gán cho Google video và kết quả địa phương Google thường xuất hiện với vị trí nổi bật.
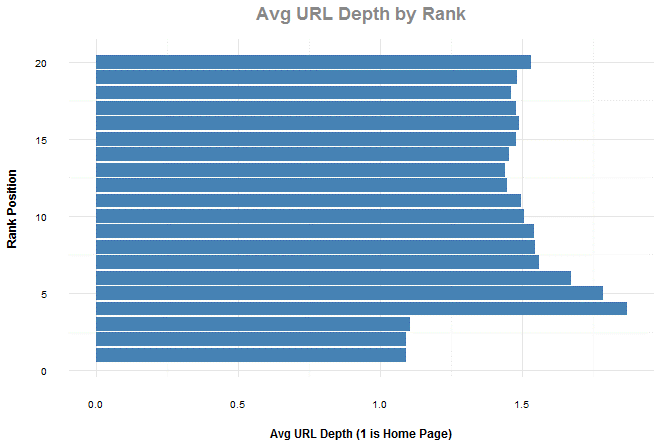
Chiều sâu đường dẫn (số thư mục con trong URL)
Với chiều sâu đường dẫn, chúng tôi lọc ra top 20 kết quả trong khắp các quan sát và đồng thời loại bỏ top bốn phần trăm các quan sát dựa trên các tên miền chứa liên kết trỏ về để loại bỏ các đường dẫn từ Google, Yelp và các trang web lớn khác. Đây là một điều thú vị vì lời khuyên thông thường là nếu bạn muốn các kết quả quan trọng nhất càng gần với gốc của trang web nhất có thể. Thêm vào đó, lưu ý về tác động của kết quả địa phương dưới phương diện độ ưu tiên với trang chủ của một trang web.
Kết luận
Tôi không nghĩ các kết quả phân tích dữ liệu của chúng tôi không gây chấn động gì, và đây chỉ là một bộ mẫu nhỏ của dữ liệu từ hơn 70 thuộc tính mà chúng tôi thu thập qua quá trình huấn luyện máy-học của mình.
Hai điều quan trọng nhất được rút ra với tôi đó là liên kết và tốc độ là lĩnh vực mà mọi người có thể tạo ra tác động nhiều nhất đến một trang web. Nội dung cần phải tốt (và cso các dấu hiệu rằng hành vi của người dùng ảnh hưởng đến thứ hạng của vài ngành dọc), nhưng bạn cần phải được thấy như mình tạo ra hành vi người dùng. Một điều thú vị nhất ở bộ dữ liệu này đó là nó hướng tới các truy vấn kiểu doanh nghiệp nhỏ hơn các nghiên cứu khác mà thu thập mẫu truy vấn trên diện rộng.
Tôi luôn là người ủng hộ thử nghiệm, hơn là việc dựa vào những gì làm tốt với người khác hoặc những gì được viết trên các blog ưa thích của bạn. GetStat và một chút JavaScript (với node) có thể đem đến cho bạn khả năng dễ dàng tập hợp các cơ chế thu thập để có cái nhìn khác về sự tương quan của kết quả đối với thị trường bạn đang làm việc. Việc có thể tiến hành các nghiên cứu kiểu này cũng giúp ích cho việc cung cấp các minh chứng cho những người không làm SEO cũng như việc tại sao chúng ta khuyến nghị mọi việc phải làm theo một cách cụ thể nào đó.
Nguồn: http://searchengineland.com/