Cộng tác viên JR Oakes đo lường chất lượng của các công cụ nghiên cứu từ khoá phổ biến với dữ liệu tìm thấy trong kết quả tìm kiếm Google và dữ liệu trang trên Google Search Console.
Bạn có bao giờ tự hỏi kết quả từ các công cụ nghiên cứu từ khoá phổ biến như thế nào khi so với thông tin mà Google Search Console cung cấp? Bài báo này xem xét việc so sánh dữ liệu từ Google Search Console (GSC) với các công cụ tìm kiếm từ khoá đáng chú ý và những gì bạn có thể trích xuất từ Google.
Thêm vào đó, bạn có thể có được dữ liệu các tìm kiếm liên quan và thứ mọi người cũng tìm kiếm từ kết quả tìm kiếm của Google bằng cách sử dụng mã lệnh ở cuối bài viết.
Bài báo này không phải là một phân tích khoa học, vì nó chỉ gồm dữ liệu từ 7 trang web. Để đảm bảo thì chúng tôi thu thập dữ liệu có phần toàn diện: chúng tôi lựa chọn các trang web từ Mỹ và Anh cùng với các ngành dọc khác nhau.
Quy trình
1. Bắt đầu bằng việc xác định các ngành liên quan tới các trang web ngành dọc
Chúng tôi sử dụng các phân mục hàng đầu của SimilarWeb để xác định các nhóm và lựa chọn các phân mục sau:
• Nghệ thuật và giải trí
• Xe cộ
• Kinh doanh và công nghiệp
• Nhà cửa và vườn tược
• Thư giãn và thú vui
• Mua sắm
• Tham khảo
Chúng tôi lấy các dữ liệu ẩn xanh từ một mẫu của các trang web của mình và có thể có được các dữ liệu không thấy được từ các chuyên gia SEO Aaron Dicks và Daniel Dzhenev. Vì phân tích ban đầu này bao gồm các thành phần định tính và định lượng, nên chúng tôi muốn dành thời gian để hiểu được quá trình và sự khác biệt hơn là mở rộng phân tích. Chúng tôi cho rằng phân tích này có thể dẫn tới một phương pháp cơ bản để các SEO nội bộ ra quyết định đúng hơn về công cụ phù hợp với ngành dọc của họ.
2. Thu thập dữ liệu GSC từ các trang web ở mỗi thị trường
Dữ liệu được thu thập từ GSC bằng cách lập trình và sử dụng ghi chú Jupyter.
Ghi chú Jupyter là một ứng dụng web mã nguồn mở cho phép bạn tạo và chia sẻ các tài liệu chứa các dòng lệnh, công thức, diễn hoạ và văn bản trực tuyến để trích xuất dữ liệu mức trang web từ Search Analytics API hàng ngày, cung cấp mức độ tinh tế hơn thứ có trong giao diện web của Google.
3. Thu thập các từ khoá xếp hạng của một trang nội bộ duy nhất với. mỗi trang web
Vì các trang chủ thường thu thập nhiều từ khoá có thể hoặc không liên quan tới nội dung thực của trang, nên chúng tôi lựa chọn một trang nội bộ hoạt động tốt để thứ hạng phù hợp hơn với nội dung trang. Điều này cũng thực tế hơn, vì người dùng có xu hướng nghiên cứu từ khoá trong bối cảnh của các ý tưởng nội dung cụ thể.
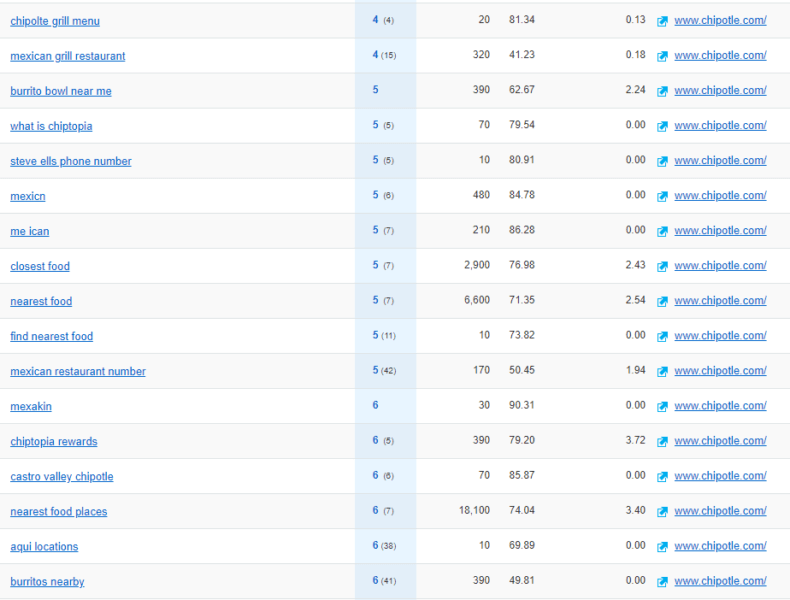
Hình ảnh phía trên là một ví dụ về xếp hạng trang cho nhiều truy vấn liên quan tới doanh nghiệp nhưng không liên quan trực tiếp tới nội dung và mục đích của trang.
Chúng tôi loại bỏ các cụm từ thương hiệu và chặn các truy vấn GSC với các kết quả trang đầu.
Cuối cùng chúng tôi lựa chọn một cụm từ chính cho mỗi trang. “Cụm từ chính” thường được sử dụng để nối về một từ khoá phổ biến với lượng tìm kiếm cao. Chúng tôi lựa chọn các cụm từ có lượng tìm kiếm cao tương đối, mặc dù không phải là cao nhất. Với các truy vấn có nhiều quảng cáo, chúng tôi lựa chọn truy vấn thể hiện trang một cách tốt nhất.
4. Tiến hành nghiên cứu tư fkhoas với nhiều công cụ và xem xét cụm từ chính
Chúng tôi sau đó sử dụng cụm từ chính được lựa chọn trong bước trên để thực hiện nghiên cứu từ khoá với ba công cụ chính: Ahrefs, Moz và SEMrush.
Tuỳ chọn “khuyến nghị tìm kiếm” và “tìm kiếm liên quan” được sử dụng, và tất cả các truy vấn trả lại được lưu giữ, cho dù công cụ có chỉ báo một thông số về khuyến nghị đó liên quan thế nào tới cụm từ chính hay không.
Dưới đây chúng tôi đưa ra số lượng kết quả từ mỗi công cụ. Thêm vào đó chúng tôi trích xuất “mọi người cũng tìm kiếm về” và “các tìm kiếm liên quan” từ Google cho mỗi cụm từ chính (với nước tương ứng) và bổ sung số lượng kết quả để đưa ra mức nền về những gì Google đưa ra miễn phí.
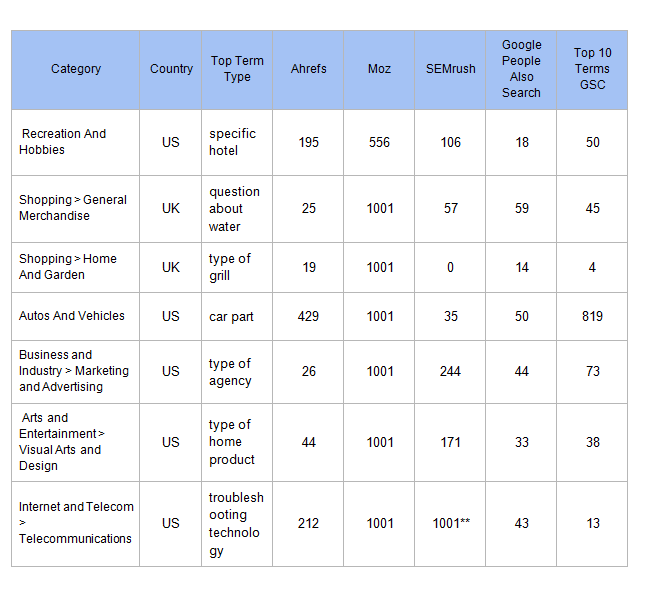
** Kết quả này trả lại hơn 5000 kết quả! Nó đã được cắt gọn lại thành 1001, là lượng con số lớn nhất có thể làm việc được và được sắp xếp theo chiều giảm.
Chúng tôi kết hợp các con số trung bình của từ khoá được trả lại theo công cụ:
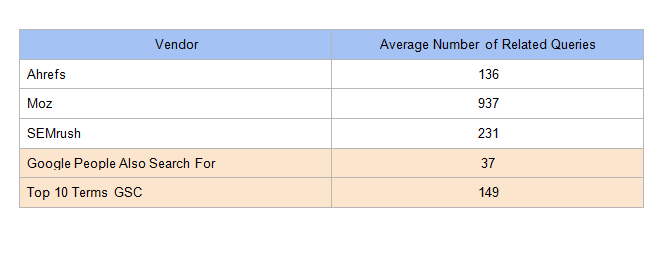
5. Xử lý dữ liệu
Chúng tôi sau đó xử lý các truy vấn với mỗi nguồn và trang web bằng cách sử dụng vài kỹ thuật xử lý ngôn ngữ để chuyển chữ thành dạng cơ bản của nó (ví dụ như “running” thành “run”), loại bỏ các từ phổ biến như “a”, “the” và “and”, thu ngắn hơn và sau đó sắp xếp các từ.
Ví dụ, quá trình này sẽ chuyển “SEO agencies in Raleigh” thành “agency Raleigh SEO”. Điều này sẽ giữ các từ quan trọng và đặt chúng theo thứ tự để ta có thể so sánh và bỏ đi các truy vấn giống nhau.
Chúng tôi sau đó tạo phần tram bằng cách chia số lượng của từng cụm từ với tổng số lượng cụm từ được trả lại trong công cụ. Điều này sẽ cho ta biết phần dư trong các công cụ.
Không may là nó không tính đến lỗi chính tả, thứ cũng gây lỗi với các công cụ nghiên cứu từ khoá ví chúng thêm vào các truy vấn không cần thiết trong kết quả. Nhiều năm trước thì việc viết sai trong các trang web là có thể nhìn ra. Ngày nay thì các công cụ tìm kiếm hoạt động thực sự tốt trong việc hiểu được điều bạn gõ, thậm chí nếu nó bị viết sai.
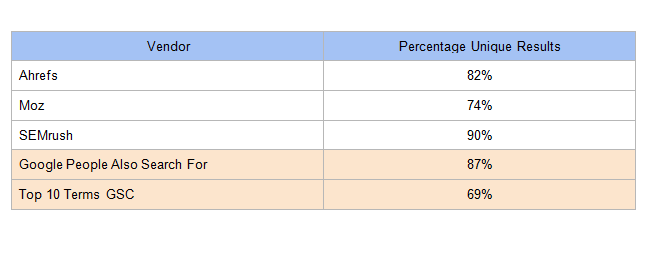
Ở bảng dưới, SEMrush có lượng phần trăm lớn nhất về các truy vấn trong khuyến nghị tìm kiếm của họ.
Điều này là quan trọng vì nếu 1000 từ khoá chỉ có 70% đặc biệt, có nghĩa là 300 từ khoá không có giá trị đặc biệt với tác vụ bạn đang thực hiện.
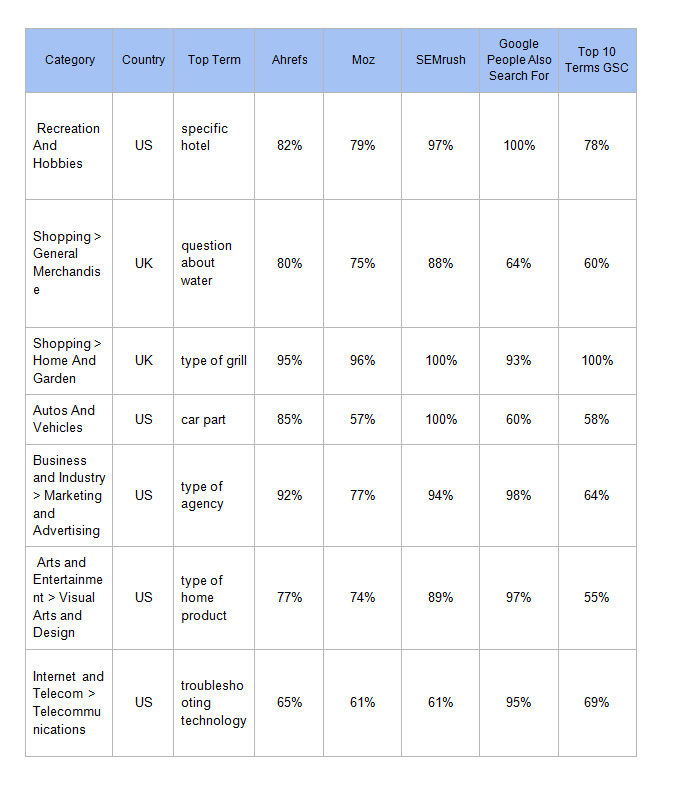
Tiếp theo, chúng tôi muốn biết các công cụ làm tốt thế nào trong việc tìm ra các truy vấn được sử dụng để tìm các trang web này. Chúng tôi lấy các cụm từ ở trên và xem xét phần trăm của các truy vấn GSC mà các công cụ có trong kết quả của chúng.
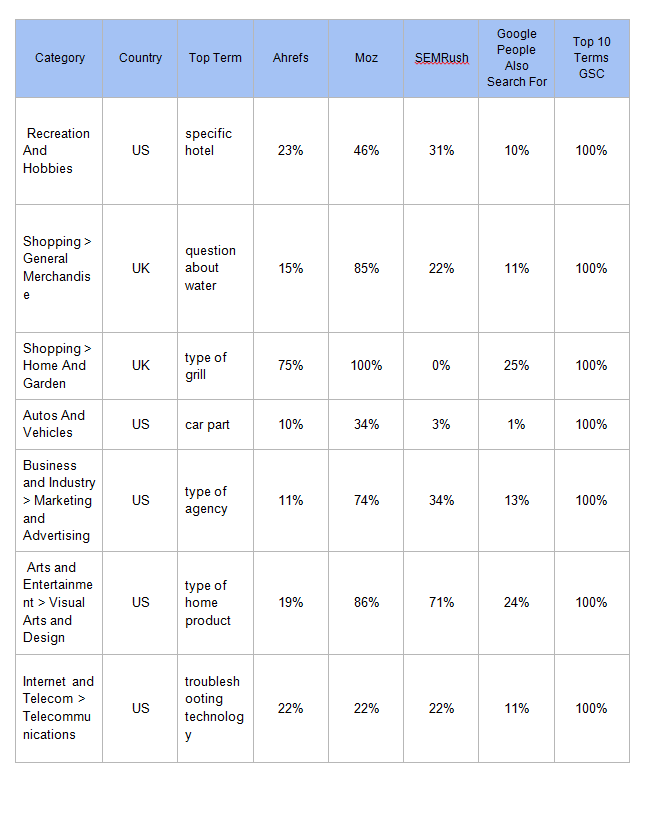
Ở bảng dưới, lưu ý về con số GSC trung bình với mỗi công cụ và việc Moz cao hơn, vì nó trả lại 1000 kết quả với phần lớn các cụm từ chính. Tất cả các công cụ đều hoạt động tốt hơn các truy vấn liên quan lấy từ Google (sử dụng mã lệnh ở cuối bài để làm tương tự).