Thiết kế tính năng
Chúng tôi thiết kế các tính năng bổ sung, thứ mà có liên quan tới xếp hạng.
Phần lớn các tính năng này là kiểu Boolean (đúng hoặc sai), nhưng vài trong số chúng là kiểu số học. Một ví dụ về tính năng Boolean là cụm tìm kiếm chính xác được bao gồm trong văn bản của trang web, trong khi đó một tính năng số học có thể là bao nhiêu thuật ngữ trong cụm tìm kiếm được bao gồm trong văn bản trang web.
Dưới đây là một số tính năng mà chúng tôi thiết kế.

Chạy TF-IDF
Với việc tiền-xử-lý các tính năng văn bản, chúng tôi sử dụng thuật toán TF-IDF (tần số cụm từ, tần số nghịch đảo). Thuật toán này xem mỗi trường hợp là một tài liệu và một bộ trường hợp là một văn thể. Sau đó nó phân chia điểm số cho mỗi cụm từ, khi mà cụm thường xuyên hơn trong tài liệu và cụm từ ít thường xuyên hơn có điểm số cao hơn.
Chúng tôi đã thử hai cách tiếp cận TF-IDF với các kết quả hơi khác nhau phụ thuộc vào mô hình. Cách tiếp cận đầu tiên bao gồm sự nối tiếp tất các các tính năng văn bản trước sau đó áp dụng thuật toán TF-IDF (ví dụ sự nối tiếp tất các các cột văn bản của một trường hợp riêng lẻ thành một văn bản, và một bộ của tất cả các văn bản đó là một văn thể). Các tiếp cận thứ hai bao gồm việc áp dụng thuật toán TF-IDF riêng rẽ với từng tính năng (ví dụ mỗi cột riêng rẽ là một văn thể), và sau đó nối tiếp các mảng kết quả.
Mảng kết quả sau khi thực hiện TF-IDF rất thưa thớt (phần lớn các cột của các trường hợp bằng 0), vì thế chúng tôi áp dụng việc giảm số chiều (giảm thành một giá trị duy nhất) để giảm số lượng của thuộc tính/cột.
Bước cuối cùng là kết nối tất cả các cột kết quả từ tất cả các nhóm tính năng thành một mảng. Chúng tôi làm điều này sau khi áp dụng tấp cả các bước trên (dọn dẹp tính năng, chuyển các tính năng chủng loại thành các nhãn và thực hiện mã hóa one-hot với các nhãn đó, áp dụng TF-IDF với các tính năng văn bản và điều chỉnh các tính năng để tập trung chúng xung quanh giá trị trung bình).
Các mô hình
Sau khi thu được và kết nối tất cả các tính năng, chúng tôi chạy một số các thuật toán khác nhau với chúng. Các thuật toán hứa hẹn nhất là bộ phân loại gradient boosting, rigde và mạng nơ ron hai lớp.
Cuối cùng chúng tôi lắp ghép các kết quả từ các mô hình sử dụng kỹ thuật trung bình đơn giản, và vì thế chúng tôi thấy có các lợi ích khác như việc các mô hình khác nhau thường có các khuynh hướng khác nhau.
Tối ưu hóa mức
Bước cuối đó là quyết định mức để chuyển một ước lượng về khả năng thành một dự đoán nhị phân (“có, chúng tôi dự đoán trang này sẽ ở trong top 10 trên Google” hoặc “không, chúng tôi dự đoán trang này sẽ không ở trong top 10 trên Google”). Để làm việc đó chúng tôi đã tối ưu một bộ đánh giá chéo và sử dụng nó để có được mức (ngưỡng) của một bộ mẫu thử nghiệm.
Kết quả
Số liệu mà chúng tôi nghĩ sẽ là đại diện nhất để đo lường hiệu quả của mô hình là ma trận nhầm lẫn. Một ma trận nhầm lẫn là một bảng thường được sử dụng để mô tả hiệu quả của một mô hình phân lớp (hoặc bộ phân lớp) với một bộ mẫu thử nghiệm mà các giá trị thật được biết.
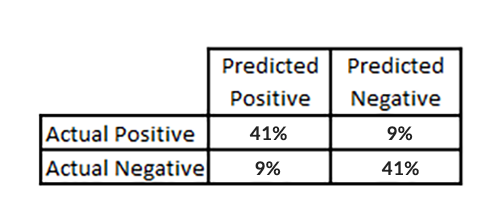
Tôi chắc là bạn đã nghe câu nói “một chiếc đồng hồ hỏng cũng đúng hai lần một ngày”. Với 100 kết quả cho mỗi từ khóa, một dự đoán ngẫu nhiên sẽ dự đoán chính xác việc “không trong top 10” 90 phần trăm. Ma trận nhầm lẫn bảo đảm rằng độ chính xác của cả các câu trả lời dương tính hoặc âm tính. Chúng tôi đạt được khoảng 41 phần trăm đúng dương tính và 41 phần trăm đúng âm tính trong mô hình tốt nhất của mình.
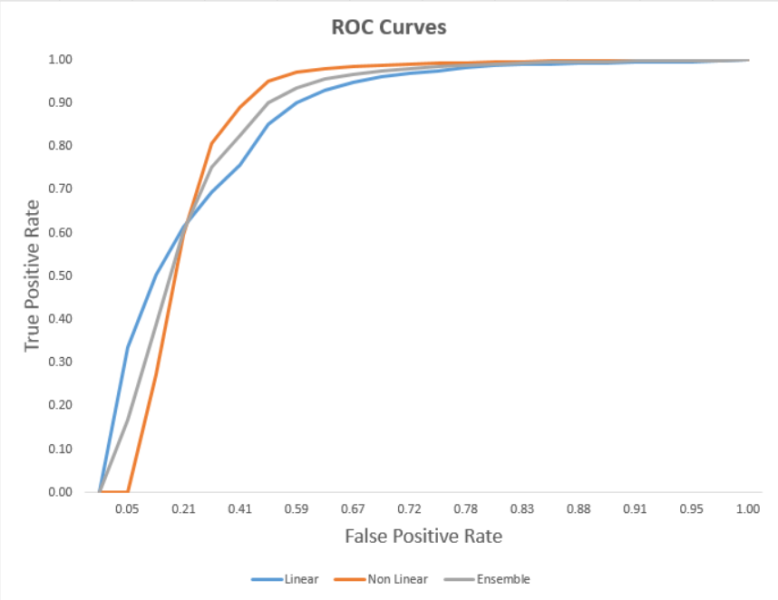
Một cách khác để diễn họa hiệu quả của mô hình là bằng cách sử dụng đường ROC. Một đường ROC là “một đồ thị điểm thể hiện hiệu quả của một hệ thống phân loại nhị phân khi ngưỡng phân biệt thay đổi. Đường này được tạo ra bằng cách vẽ các điểm tỷ lệ đúng dương tính so với tỷ lệ sai dương tính ở các thiết lập mức khác nhau”. Các mô hình không tuyến tính được sử dụng là XGBoost và mạng nơ ron. Mô hình tuyến tính là hồi quy lô gic. Đồ thị mô hình thể hiện sự kết hợp của mô hình tuyến tính và không tuyến tính.
XGBoost là viết tắt của “Extreme Gradient Boosting”, với gradient boosting là “một kỹ thuật máy học cho việc hồi quy và phân loại vấn đề, thứ sản xuất ra một mô hình dự đoán dưới dạng một mô hình của các mô hình dự đoán yếu, thường là dạng cây quyết định”.
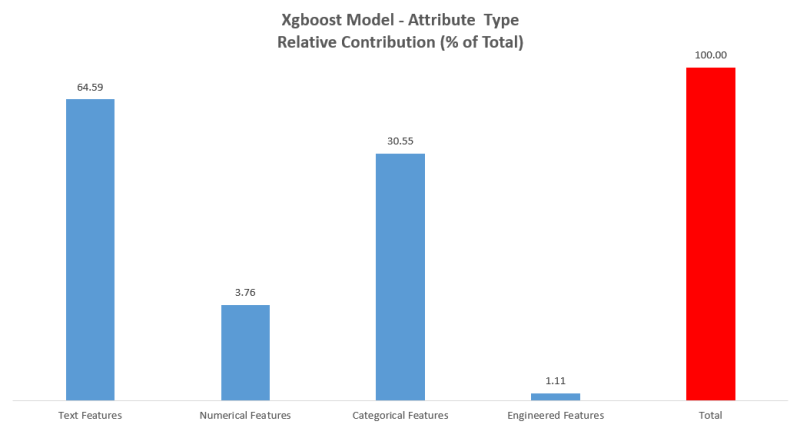
Đồ thị dưới đây cho thấy sự đóng góp tương đối của các chủng loại tính năng tới sự chính xác của dự đoán cuối cùng của mô hình. Không giống như các mạng nơ ron, XGBoost cùng với các mô hình cụ thể khác cho phép bạn dễ dàng nhìn mô hình để xem đối trọng dự đoán tương đối mà tính năng cụ thể nào đó nắm giữ.
Chúng tôi khá ấn tượng vì chúng tôi có thể xây dựng được mô hình cho thấy sức mạnh dự đoán từ những tính năng mà chúng tôi đưa cho nó. Chúng tôi khá lo ngại rằng sự giới hạn các tính năng sẽ dẫn tới sự thất bại của dự án này. Về lý tưởng là chúng tôi sẽ có một cách để thu thập dữ liệu của toàn bộ một trang web để có được sự liên quan tổng thể. Có lẽ chúng tôi có thể thu thập dữ liệu từ số lượng đánh giá Google mà một doanh nghiệp có được. Chúng tôi cũng hiểu rằng Google có nhiều dữ liệu tốt hơn về các liên kết và trích dẫn hơn cả những gì chúng tôi từng hy vọng có thể tập hợp được.
Những gì chúng tôi học hỏi được
Máy-học là một công cụ mạnh mẽ có thể được sử dụng thậm chí khi bạn không hiểu được đầy đủ sự phức tạp về việc nó làm việc thế nào. Tôi đã đọc nhiều bài báo về RankBrain và sự bất lực của các kỹ sư để hiểu được nó làm việc thế nào. Đây là một phần của phép màu và vẻ đẹp của máy-học. Giống như là quá trình tiến hóa, trong đso cuộc sống có được các tính năng khác nhau và có sự sống và cái chết, quá trình máy-học tìm ra cách đến với câu trả lời thay vì việc được đưa cho câu trả lời.
Trong khi chúng tôi thấy vui với các kết quả từ các mô hình đầu tiên của mình, điều quan trọng là hiểu được rằng nó được huấn luyện dựa trên một lượng mẫu tương đối nhỏ khi so sánh với kích thước rộng lớn của internet. Một trong những mục tiêu chính trong việc xây dựng bất cứ công cụ máy-học nào là ý tưởng về việc tạo ra và vận hành hiệu quả trên những dữ liệu mà chúng chưa hề thấy trước đây. Chúng tôi đang thử nghiệm mô hình của mình với những truy vấn với và sẽ tiếp tục tinh chỉnh.
Điều rút ra lớn nhất với tôi trong dự án này là bắt đầu có sự hiểu biết về giá trị to lớn mà máy-học có với ngành của chúng ta. Vài hướng mà tôi thấy nó ảnh hưởng đến SEO là:
• Tạo, tổng hợp và phân loại văn bản. Hãy nghĩ về các trích đoạn thông minh cho nội dung và các trang web có khả năng tự sắp xếp dựa trên phân loại.
• Sẽ không bao giờ phải viết thông số ALT nữa.
• Những cách mới để xem xét hành vi người dùng và phân loại/chấm điểm khách ghé thăm.
• Sự tích hợp các phương cách mới để điều hướng trang web sử dụng giọng nói và hệ thống kiểu hỏi&trả lời về nội dung/sản phẩm/khuyến nghị.
• Những cách mới hoàn toàn để thu thập thống kê và thu thập dữ lieuej để có hiểu biết về khách ghé thăm, các phân mục, xu hướng và khả năng hiển thị.
• Các công cụ thông minh hơn trong phân phối các kênh quảng cáo đến người dùng có liên quan.
Dự án này thiên về những gì mà chúng tôi học hỏi được hơn là đạt được một điều thần kỳ. Giống như lời khuyên mà tôi đưa cho các nhà phát triển mới (“những hiểu biết tốt nhất có khi làm việc”), điều quan trọng là xắn tay vào làm việc và bắt đầu các huấn luyện. Bạn sẽ học được cách để thu thập, dọn dẹp và sắp xếp dữ liệu, và bạn sẽ làm cho bản thân quen thuộc với những chi tiết của các công cụ máy-học.
Phần lớn điều này quen thuộc với giới kỹ thuật SEO, nhưng ngành cũng đang phát triển những công cụ để giúp những ai không chuyên về kỹ thuật. Tôi có biên soạn một số tư liệu dưới đây cho những ai thích tìm hiểu lĩnh vực này.
Các công nghệ hiện thời được ưa thích
Điều quan trọng phải hiểu rằng phần lớn máy-học không phải là xây dựng một trí thông minh nhân tạo với trình độ hiểu biết của con người, mà là việc sử dụng dữ liệu để giải quyết các vấn đề thực tại. Dưới đây là vài ví dụ về các cách hiện thời mà điều đó đang diễn ra.
NeuralTalk2
NeuroTalk2 là một mô hình Torch của Andrej Karpathy dùng để tạo ra các mô tả ngôn ngữ tự nhiên cho những hình ảnh cho trước. Hãy tưởng tượng việc không bao giờ phải viết thông số ALT một lần nào nữa và để máy móc làm cho mình. Facebook đã tích hợp công nghệ này (http://www.theverge.com/2016/4/5/11364914/facebook-automatic-alt-tags-blind-visually-impared).
Trình thu thập Microsoft và Alexa
Các nhà nghiên cứu đang làm chủ việc xử lý giọng nói và đang bắt đầu có thể hiểu được ý nghĩa sau những lời nói (với tình huống cho trước). Điều này có ý nghĩa sâu sắc với các trang web truyền thống trong việc làm thế nào thông tin được truy cập. Thay vì điều hướng và tìm kiếm, trang web có thể có một cuộc trao đổi với khách ghé thăm. Trong trường hợp Alexa thì không có trang web nào cả, chỉ là hội thoại.
Xử lý ngôn ngữ tự nhiên
Có một lượng lớn công việc đang diễn ra trong lĩnh vực dịch thuật và ngữ nghĩa nội dung. Nó vượt xa các chuỗi Markov truyền thống và các đại diện n-gram của văn bản. Máy-học cho thấy các gợi ý về khả năng tổng kết và tạo ra văn bản trong khắp các tên miền. “Hiệu quả không hợp lý của các mạng lưới nơ ron hồi quy” (http://karpathy.github.io/2015/05/21/rnn-effectiveness/) là một bài viết hay từ năm ngoái cho ta thấy sơ bộ về những gì có thể ở đây.
Thi đấu về độ liên quan tìm kiếm của Home Depot
Home Depot gần đây tài trợ cho một cuộc thi đấu mở trên Kaggle để dự đoán về độ liên quan của các kết quả tìm kiếm của họ với truy vấn của khách ghé thăm. Bạn có thể xem vài quá trình đằng sau các người chiến thắng ở chủ đề này (https://www.kaggle.com/c/home-depot-product-search-relevance/forums/t/20427/congrats-to-the-winners).
Làm thế nào để bắt đầu với máy-học
Bởi vì chúng ta, những người marketing tìm kiếm, đang sống trong một thế giới của dữ liệu, điều quan trọng với chúng ta là hiểu được các kỹ thuật mới cho phép chúng ta ra các quyết định tốt hơn trong công việc của mình. Có nhiều lĩnh vực mà máy-học có thể giúp ích cho hiểu biết của chúng ta, từ việc hiểu rõ hơn về mục đích người dùng đến hành vi trang web nào thúc đẩy hành động nào.
Với những ai thích tìm hiểu về máy-học nhưng quá tải với sự phức tạp của nó, tôi khuyến nghị Data Sciene Dojo. Chúng là những hướng dẫn đơn giản sử dụng Machine Learning Studio của Microsoft rất dễ tiếp cận với người mới. Điều này cũng có nghĩa bạn không phải học lập trình trước khi xây dựng các mô hình đầu tiên của mình.
Nếu bạn thích tìm hiểu về các mô hình tùy chỉnh mạnh mẽ hơn và không ngại lập trình một chút, tôi sẽ bắt đầu với việc nghe bài giảng này của Justin Johnson ở Stanford (http://cs231n.stanford.edu/slides/winter1516_lecture12.pdf) khi nó có mặt trong bốn thư viện phổ biến nhất. Một hiểu biết tốt về Python (và có lẽ là R) là cần thiết để làm bất cứ việc gì. Christopher Olah có một trang blog khá tuyệt bao hàm nhiều chủ đề thú vị liên quan đến khoa học dữ liệu.
Cuối cùng, Github (https://github.com/) là người bạn của bạn. Tôi thấy bản thân mình xem qua các mục được thêm vào để thấy các dự án cực kỳ thú vị mà mọi người đang tiến hành. Trong nhiều trường hợp, dữ liệu luôn sẵn có và có các mô hình đã được đào tạo có thể tiến hành các công việc cụ thể rất tốt. Xem xét xung quanh và làm cho bản thân thân thuộc với các khả năng sẽ cho bạn quan điểm về lĩnh vực tuyệt vời này.
Nguồn: http://searchengineland.com/