Môi trường phát triển web thông minh (nguồn: https://en.wikipedia.org/wiki/Semantic_Web_Stack)
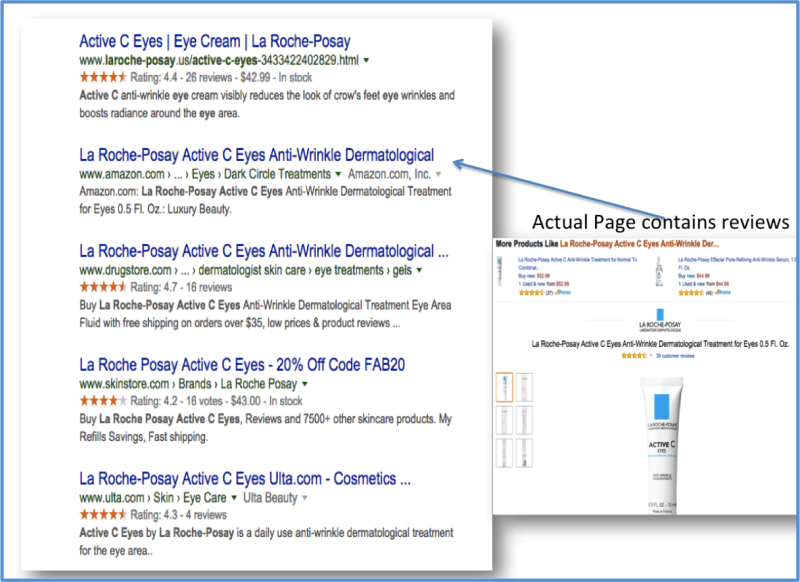
Độ tin cậy đạt được thông qua việc chứng minh mức tin cậy của các nguồn dữ liệu và sử dụng logic hình thức khi trích xuất thông tin mới. Máy tính nâng cao hoặc học hỏi yếu tố này từ hành vi của con người để đưa ra các thuật toán có khả năng đưa ra các kết quả tìm kiếm phù hợp với người dùng. Xếp hạng kết quả tìm kiếm dựa trên độ tin cậy Xếp hạng kết quả tìm kiếm dựa trên độ tin cậy, thực ra là tên của một bằng sáng chế mà Google đăng ký tháng Chín 2012. Bằng sáng chế này mô tả làm thế nào các yếu tố tin cậy có thể được kết hợp vào để tạo ra một “bậc tin cậy”, thứ mà có thể sau đó có thể được sử dụng để thay đổi xếp hạng kết quả tìm kiếm trong vài trường hợp. Mọi người thường tin tưởng thông tin từ nguồn mà họ thấy đáng tin, vì thế hiển thị kết quả tìm kiếm cho người dùng từ những nguồn họ thấy đáng tin là hợp lý (và đồng thời mang đến sự cá nhân hóa). Một nhóm làm việc tại Google gần đây có viết một bài báo: Knowledge-Based Trust (Kiến thức cơ sở độ tin cậy): Ước lượng độ tin cậy của các nguồn website. Bài báo luận đàm về việc sử dụng điểm số độ tin cậy – Knowledge-Based Trust (KBT) – thứ được tính toán dựa trên các yếu tố mà họ mô tả trong bài báo. Dưới đây tôi trích dẫn vài điểm nổi bật từ bài báo trên mà tôi tin là có giá trị dưới góc nhìn của SEO: Chúng tôi đề nghị sử dụng Knowledge-Based Trust (KBT) để ước lượng độ tin cậy của nguồn như sau. Chúng tôi trích xuất nhiều sự việc từ nhiều trang sử dụng các kỹ thuật trích xuất thông tin. Sau đó chúng tôi cùng nhau ước lượng độ chính xác của các sự việc này và độ chính xác của các nguồn sử dụng suy luận từ một mô hình xác xuất. Suy luận là một quá trình tái lặp, vì thế chúng tôi tin rằng một nguồn chính xác nếu như các sự việc của nó chính xác, và chúng tôi tin rằng các sự việc chính xác nếu như chúng được trích xuất từ một nguồn chính xác. Qúa trình trích xuất sự việc mà chúng tôi sử dụng dựa trên dự án Knowledge Vault (Khung kiến thức - KV) [10]. KV sử dụng 16 hệ thống trích xuất thông tin khác nhau để trích xuất (chủ đề, vị ngữ, đối tượng) kiến thức từ các trang web. Một ví dụ về việc trích xuất này là (Barack Obama, quốc tịch, USA). Một chủ đề đại diện cho một thực thể thực tế, xác định bằng một ID giống như các mid trong cơ sở dữ liệu Freebase [2]; một vị ngữ được định nghĩa trước trong Freebase, mô tả một đóng góp cụ thể của thực thể; một đối tượng có thể là một thực thể, một chuỗi, một giá trị số, hoặc ngày tháng. Tôi cũng thích nhất đoạn giới thiệu sau: Đánh giá chất lượng của các nguồn web rất quan trọng với tìm kiếm web. Thường thì nó được đánh giá dựa trên các dấu hiệu bên ngoài như các siêu liên kết và lịch sử trình duyệt. Tuy nhiên, các dấu hiệu đó chủ yếu nắm bắt về độ phổ biến của trang web. Ví dụ như các trang web tin đồn thất thiệt được nêu ra ở [16] chủ yếu có điểm số xếp hạng PageRank cao, nhưng không được xem là đáng tin. Ngược lại, một số trang ít phổ biến hơn nhưng có thông tin rất chính xác. Điều có thể rút ra được từ đây đó là người làm SEO nên đảm bảo rằng tất cả các văn bản trên bất cứ trang web hoặc blog nào đều là sự thật, vì điều này có thể làm tăng độ tin cậy (điều mà ngày nào đó có thể tác động đến xếp hạng). Khi tìm kiếm trên Google, rõ ràng là họ sử dụng một cơ chế dựa trên độ tin cậy ở dạng nào đó. Người dùng thường tin tưởng các đánh giá trên mạng, vì thế các đánh giá và lượng đánh giá sẽ có ích cho người dùng khi họ tìm kiếm một sản phẩm cụ thể. Như trong trường hợp tìm kiếm cho sản phẩm “La Roche Posay Vitamin C eyes” đem lại các kết quả sau đây trong trang kết quả tìm kiếm tự nhiên: